01
Detect change
Container image tag, env var, replicas, probe, or rollout-strategy diff is observed in the cluster.

Metoro watches every rollout against live production behavior. Regressions are caught in under 60 seconds, with a rollback PR pre-drafted and the evidence in your Slack channel.











Modern engineering teams deploy to Kubernetes dozens of times per day. Each deployment can introduce a production regression: a subtle memory leak, a misconfigured environment variable, or a breaking API change that only appears under real traffic.
Traditional deployment monitoring falls short. Health checks only catch crashes. Canary deployments require complex traffic-splitting infrastructure. Manual verification does not scale when teams ship multiple times daily. The result is that deployment issues are often discovered through user complaints, not proactive detection.
Post-mortems often reveal the same pattern: the signals were already there in the logs, traces, and metrics, but no one connected them to the deployment that caused the regression until users had already been impacted.
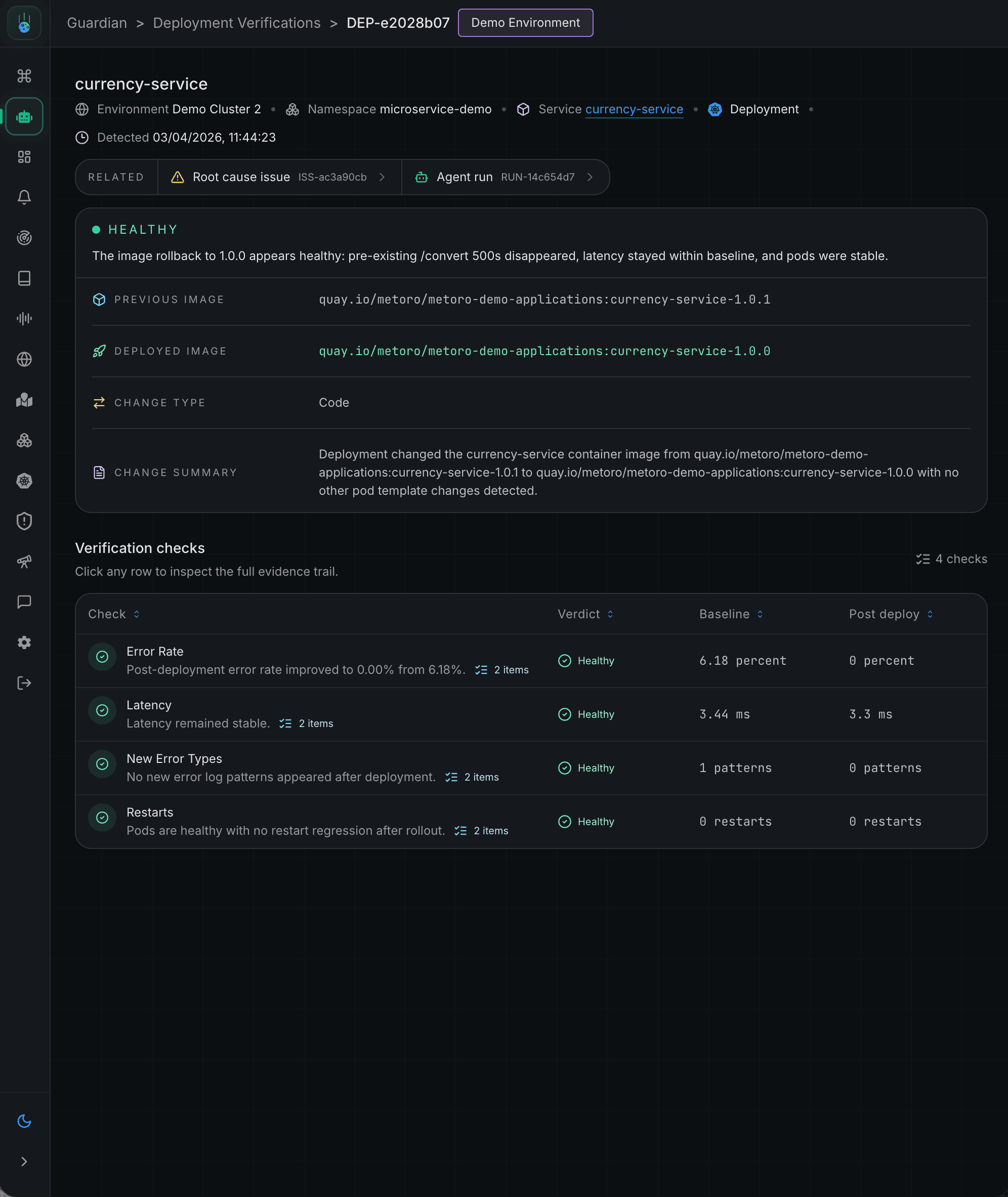
Metoro verifies every Kubernetes rollout by analyzing production behavior before and after deployment, then tells teams whether the release is healthy or degraded within minutes.
The same evidence is packaged for the team: Slack updates, correlated telemetry, and remediation context when a release starts to hurt production.
Technical docsMetoro compares pre and post-deployment logs, traces, metrics, and Kubernetes events automatically.
Degraded deployments include the affected service, supporting signals, Slack updates, and remediation context for reviewers.
Metoro watches your cluster, picks up every change, and runs a verification job against real traffic - automatically.
Container image tag, env var, replicas, probe, or rollout-strategy diff is observed in the cluster.
Metoro reasons about what the change implies and selects the right signals to compare against baseline.
Live traffic from the new pods is compared against baseline across error rate, latency, log patterns, and pod health.
Healthy, Regression, or Inconclusive - with full evidence trail and a rollback PR if needed.
You don't get a vague "looks healthy." You get the checks that ran, the baselines they compared against, the post-deploy values, and the underlying signals behind every number.
Metoro doesn't just watch a CPU graph. Each verification compares a wide surface of signals against the pre-deploy baseline - picked dynamically based on what actually changed.
Metoro classifies what kind of change rolled out and tunes the verification accordingly. A replica bump runs differently than an image change.
| Change type | What Metoro looks at | Check window | Severity |
|---|---|---|---|
| Image / code | What Metoro looks atError rate, new error types, latency, downstream regressions | Check window30–90s | SeverityHigh |
| Env var change | What Metoro looks atAffected paths, config-driven branches, restart loops | Check window20–60s | SeverityHigh |
| Resource limits | What Metoro looks atCPU throttling, OOMKills, p99 latency under saturation | Check window60–120s | SeverityMedium |
| Replica scale | What Metoro looks atPer-pod warmup, cache hit recovery, downstream load | Check window20s | SeverityLow |
| Probe change | What Metoro looks atLiveness / readiness flapping, traffic loss | Check window30–60s | SeverityHigh |
| Rollout strategy | What Metoro looks atSurge / unavailable behavior during the rollout itself | Check windowrollout | SeverityMedium |

Every verification posts a thread to your deployments channel - change detected, reason for verification, ETA, then verdict with a one-click link to the full evidence and the rollback PR.
Metoro sits at the cluster level - it sees every change regardless of which CD tool deployed it.
Syncs, health, app-of-apps
Correlates Argo application events with the Kubernetes diff that changed prod.
GitRepository, Kustomization, HelmRelease
Reads GitOps changes as they land, then verifies the resulting workload behavior.
Upgrades and rollbacks
Tracks chart-driven pod-template changes without requiring release scripts.
apply, patch, scale
Catches direct cluster changes even when they bypass the normal deploy path.
Pipeline events and deploy stages
Links pipeline-triggered deploys to the live signals used for the verdict.
Rollback PRs against the deploy repo
Opens the remediation path where the team already reviews production changes.
Merge requests and deploy flow
Uses the same evidence trail for GitLab-hosted release and rollback work.
Job-triggered deploys
Keeps legacy and custom jobs covered by the same verification path.
Canary controls traffic. APM shows symptoms. Metoro connects the deployment change to live behavior and returns a verdict.
Metoro has made visibility into our Kubernetes environment effortless with on-demand event analysis and AI-driven root-cause investigations. Nothing is hidden anymore.
Metoro absolutely slaps, so good ❤️
Detection, investigation, and the fix PR - all before I finished reading the page. It's the first AI SRE that's actually earned its name.
Metoro has been a huge boon to our observability ecosystem; saving us time and effort getting the information we care about most out of our clusters. The only thing cooler than the tool has been the people behind it.
It found exactly what I was looking for in the logs. Amazing.
We used to spend an hour digging through dashboards when something broke. Now Metoro figures it out in minutes - our on-call engineers love it.
AI root cause analysis is just amazing. Helps us save a ton of time.
We installed Metoro, and it just worked.
I'm literally able to look up at a Slack notification from Metoro whilst having noodles, tap the link, access the Metoro dashboard, see what customers on Porter Cloud are doing and take a call in real-time. For me, that's the best thing ever.
In the last week, we've detected and blocked 10 malicious agents running on our infrastructure. Without Metoro, they would still likely be running.
Metoro made it incredibly simple for us to not just observe and trace logs, but also to dive into AI-driven investigations effortlessly - turning complex Kubernetes monitoring into a smooth, intuitive experience.
Anyone running user agents on their infrastructure needs a solution like Metoro. It's just a case of when, not if a malicious agent will be running.
AI Deployment Verification is an automated process that analyzes every Kubernetes deployment to detect breaking changes before they impact users. Instead of relying on basic health checks or manual monitoring, it uses AI to correlate multiple data sources and identify regressions within minutes of deployment.
The verification process compares pre and post-deployment telemetry to catch issues like increased error rates, latency spikes, memory leaks, and failed downstream calls. It delivers a clear verdict - healthy or degraded - with specific evidence so teams can act immediately.
Operational in less than 5 minutes. No code changes. No config to maintain.